Introduction -
Distributed Database Architecture -
Today's business environment has an increasing need for distributed databases as the desire for reliable, scalable and accessible information is steadily rising. Distributed Database Management Systems (say DDBMS) are an extension of the client / server technology where machine (say Node) takes a role as a client or server or both. DDBMS consists of several databases running on different servers and while being networked together and locally accessed as independent databases in their own right allow some privileged users to look upon this set up as logically a single large database. Rather, the users have no knowledge of those multiple databases running on different servers and they may perform the transactions and manipulations on the data in the same way as they would when connected to a normal single database set up.
Distributed Database Architecture -
 |
| Oracle's Distributed Database Architecture |
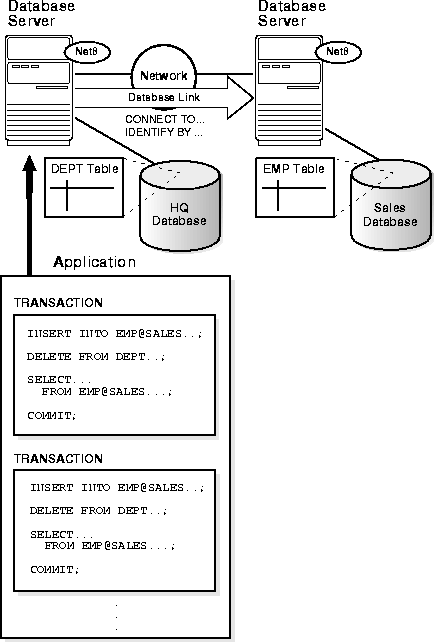
On the right hand side is the diagram which represents the Oracle's Distributed Database Architecture and has been reproduced here from Oracle's documentation for our discussion and reference (DDBMS from other vendors use more or less the similar concept if not exact) -
At the center of the idea of DDBMS is the concept of communication channel between the databases called "Database Link" (say dblink). It is a logical object defined in the database (local database) which wants to share the data from a remote database on the request of the user (say application). It is unidirectional in the sense that the data over a dblink can flow from remote database toward the database (local database) which has defined the dblink (in the opposite of the direction of the link in the picture). However, the name of the dblink is derived with "Global Database Name" of the remote database. The global database name is formed by prefixing the database name with the database's domain name so that the global database name becomes unique throughout the world. For example sales.etrixdatasolutions.com. Further, an object "name resolution" is done in distributed environment by using unique object name qualifier formed by combining schema name and object name with an address of the global database name in which the object resides. For example - a table "emp" in "scott" schema in "sales" database may be referenced as scott.emp@sales.etrixdatasolutions.com. All the nodes apart from wired in any basic network protocol (like TCP/IP) of choice have Oracle's own network protocol NET8 riding over the basic protocols to provide heterogeneous network / communication environment among all the nodes. In general terms, the node which requests for the data is termed as "client" and the one which serves the request is called "server" which typically has installed Database Management System Software managing a database. There may be several servers (databases) networked together as above with appropriate dblinks created among them.
How Distributed Database System (DDBMS) works -
In the figure above we may consider the application to be running on a PC (say Client), issuing some statements seeking to perform the "transaction" (say Operation on data) in local database (HQ database to which it is physically connected) together with a few statements directed towards remote database (Sales database). Then for the part of the transaction statements and the tables residing on the local database (HQ) it acts as a server and takes the role as a client (say broker) while "brokering" the request for the remote database (Sales). In the same way the changes which are part of one transaction may be "committed" with a single "commit" statement by the user (application) and changes will be saved to the respective databases. The whole transaction mechanism as such works in a "seamless" manner, transparent to the application.
Why use Distributed Database System -
The motivation for using the DDBMS comes from the following advantages -
How Distributed Database System (DDBMS) works -
In the figure above we may consider the application to be running on a PC (say Client), issuing some statements seeking to perform the "transaction" (say Operation on data) in local database (HQ database to which it is physically connected) together with a few statements directed towards remote database (Sales database). Then for the part of the transaction statements and the tables residing on the local database (HQ) it acts as a server and takes the role as a client (say broker) while "brokering" the request for the remote database (Sales). In the same way the changes which are part of one transaction may be "committed" with a single "commit" statement by the user (application) and changes will be saved to the respective databases. The whole transaction mechanism as such works in a "seamless" manner, transparent to the application.
Why use Distributed Database System -
The motivation for using the DDBMS comes from the following advantages -
- The development of computer networks promote decentralization - Networks allow the data sharing from remote servers and so there is no need all the data of an organization to be stored on a single server (and hence rely on that single server).
- The organizational structure of the company might be reflected in the database organization - A company consists of different units (say departments) for carrying out its business and it is possible that each department may be provided with a database to work from it.
- Capacity and Incremental growth - Expand as you go is always an economical option for every business instead of investing in the hardware with anticipated growth.
- Reliability and availability - DDBMS allow the replication of the data across several nodes. Hence the failure of a node still allows access to the replicated copy of the data from another node.
- Reduced communication overhead - Equally advantageous is the characteristic of the data replication to store the data close to its anticipated use. This also helps in reducing communication overhead.
"Distributed Database" Vs. "Distributed Processing" -
These two terms have distinct meanings yet closely related to each other. While "Distributed Databases" are well defined here before, the "Distributed Processing" occurs when an application system distributes its tasks among multiple computers in a network. For example an application designating the server (local) to which it is connected as "broker" to process its data request from the remote database, so the local server apart from being a server becomes a client to serve the application's such requests.
"Distributed Database" Vs. "Database Replication" -
Distributed Database System does not always mean replication of the data. However Database Replication is a possibility in the DDBMS. In a pure DDBMS, there is a single copy of data and supportive objects on the respective servers, whereas replication is the process of copying and maintaining database objects in multiple databases that makeup a distributed database system.
DDBMS characteristics in nutshell -
- Collection of logically related shared data.
- Data split into fragments.
- Fragments may be replicated.
- Fragments / replicas allocated to sites (nodes).
- Sites linked by communication network.
- Data at each site is under control of DBMS.
- DBMSs handle local operations autonomously.
- Each DBMS participates in at-least one global application.
So here was a brief introduction to the DDBMS, however there is technological side to the operation of the Distributed Database Management System. Click Here for continued reading to "Distributed Database System - Principles"
shared on facebook..
ReplyDelete